Check out the journal article about this project.
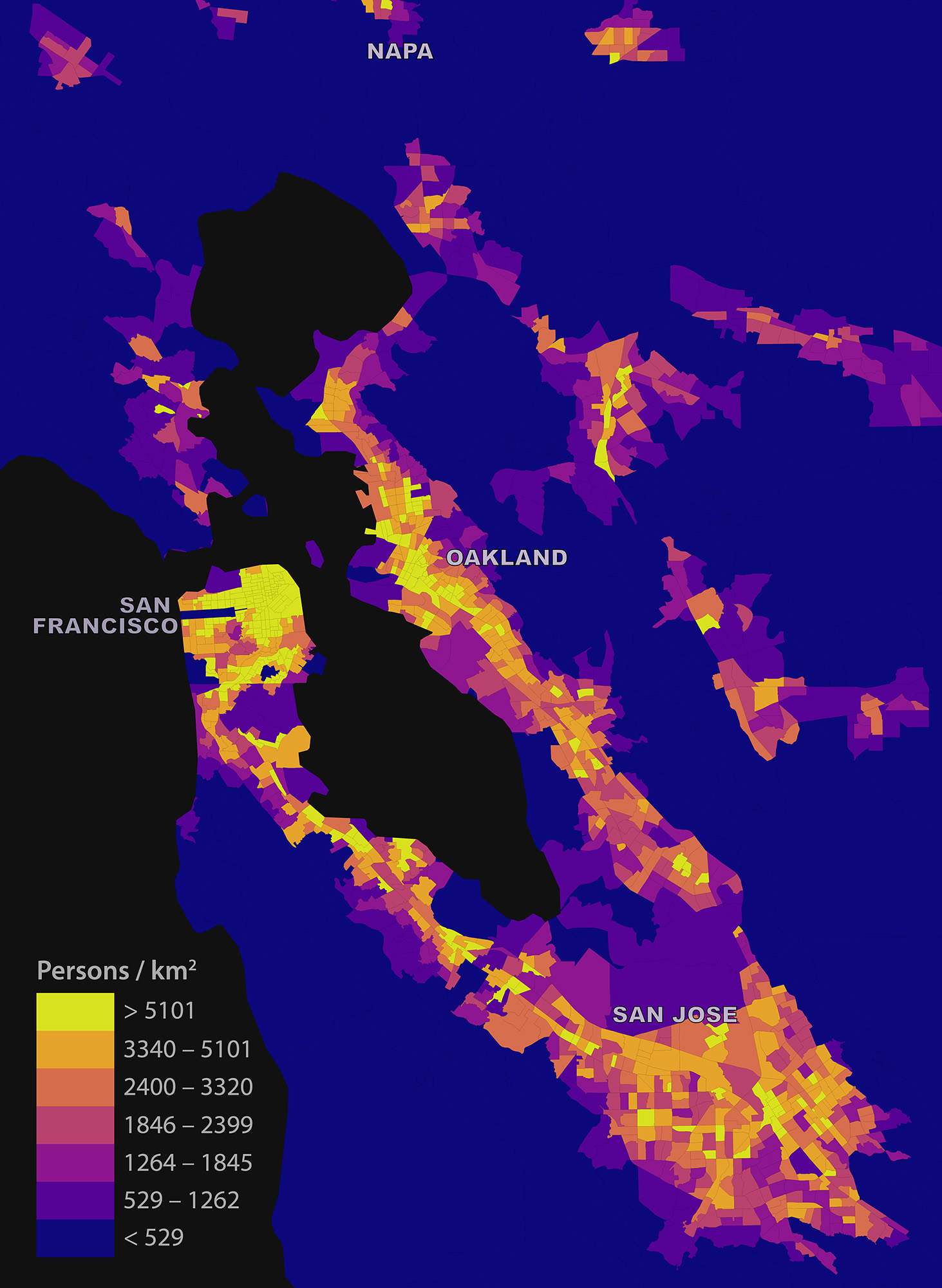
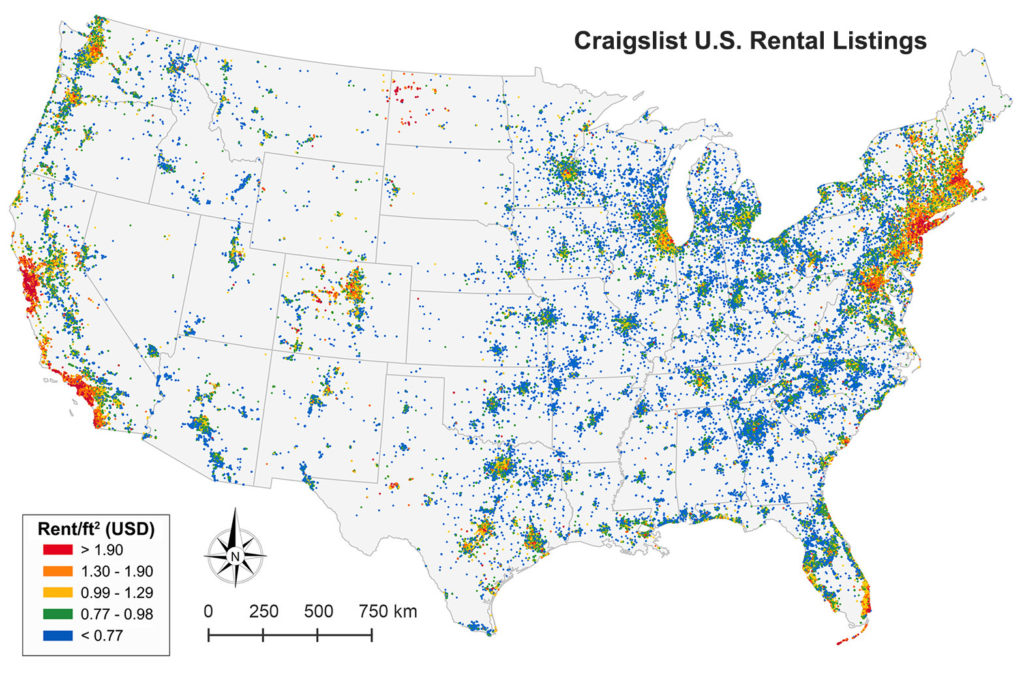
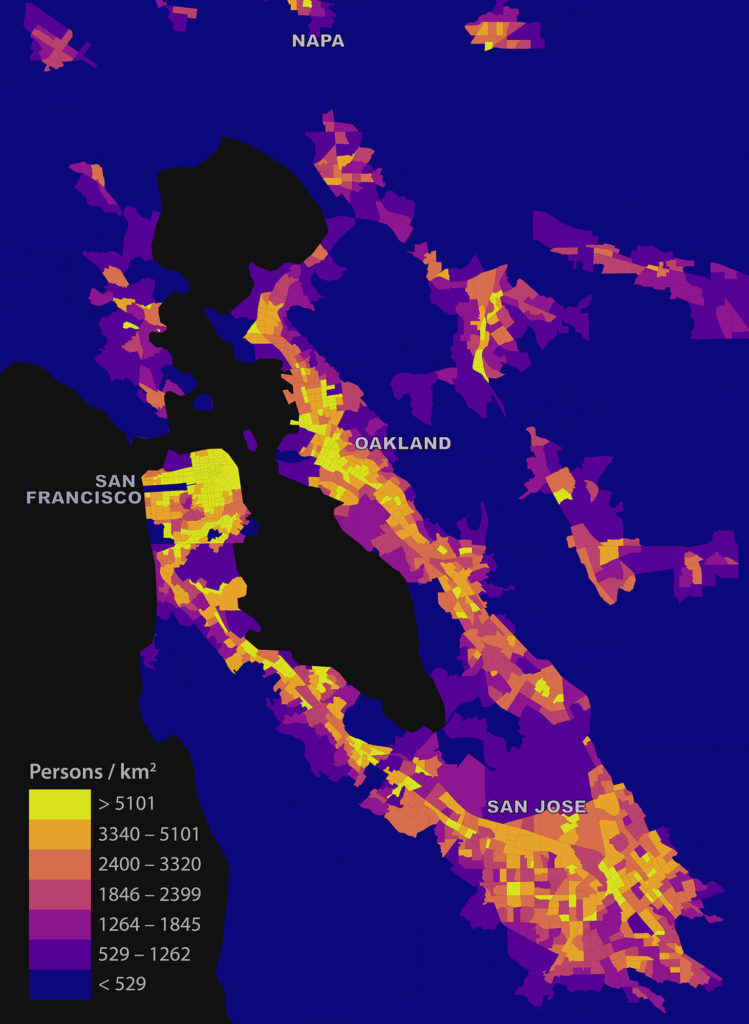
I was recently asked: “how might someone figure out the local daytime population density across the Bay Area from public data?” My answer, in short, was that you really couldn’t accurately. But you could at least produce a coarse, biased estimate. Here’s how.
I examined the Bay Area’s tract-level daytime population density using three input data products: the 2010 TIGER/Line census tracts shapefile with DP1 attributes, the 2010 California LEHD LODES data, and the census bureau’s 2010 US states shapefile. I preferred the 2010 census demographic data to (more recent) ACS data because the ACS tract-level variables are five-year rolling averages. Given this, I preferred not to compare 2014 LODES data to 2010-2014 ACS data as the Bay Area experienced substantial housing, economic, and demographic upheaval over this interval – patterns obscured in the ACS rolling average. To avoid inconsistent comparison, I opted for more stale – but more accurate and comparable – data.
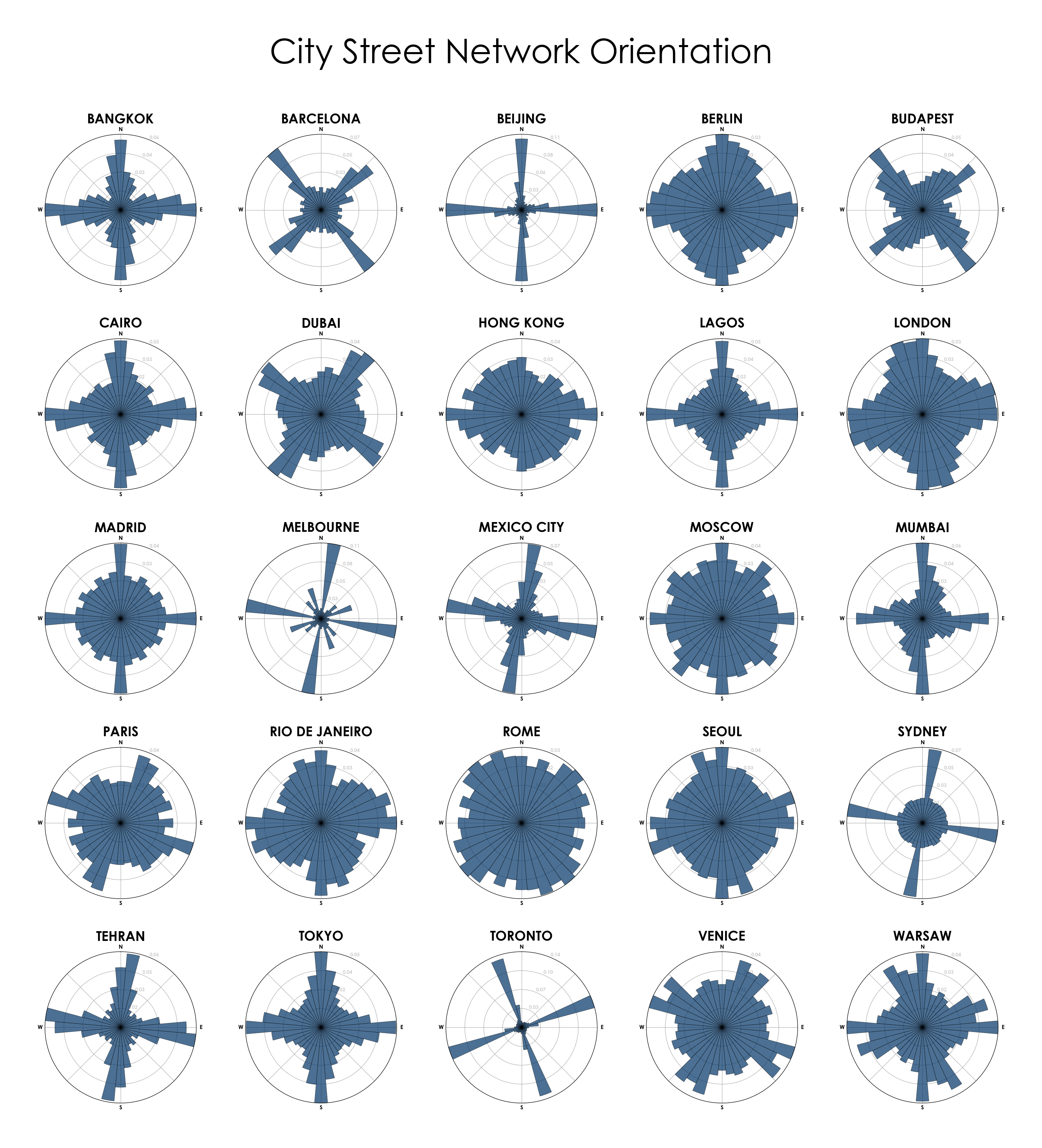
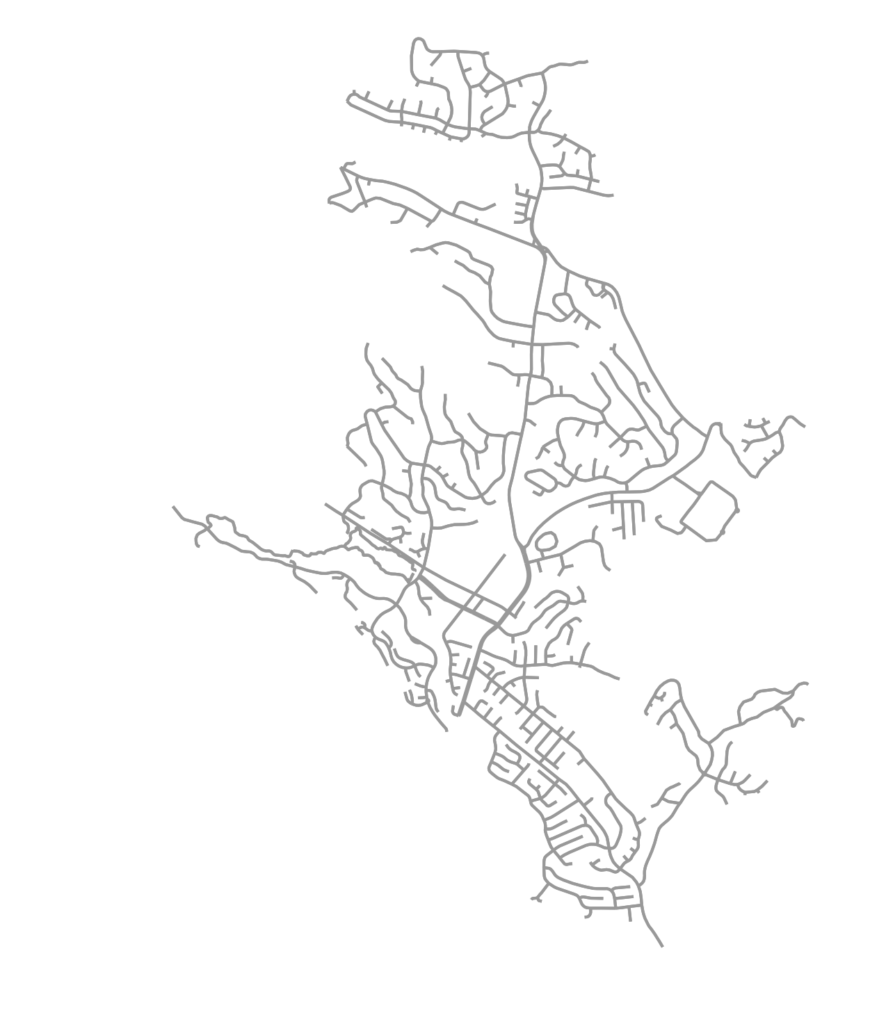
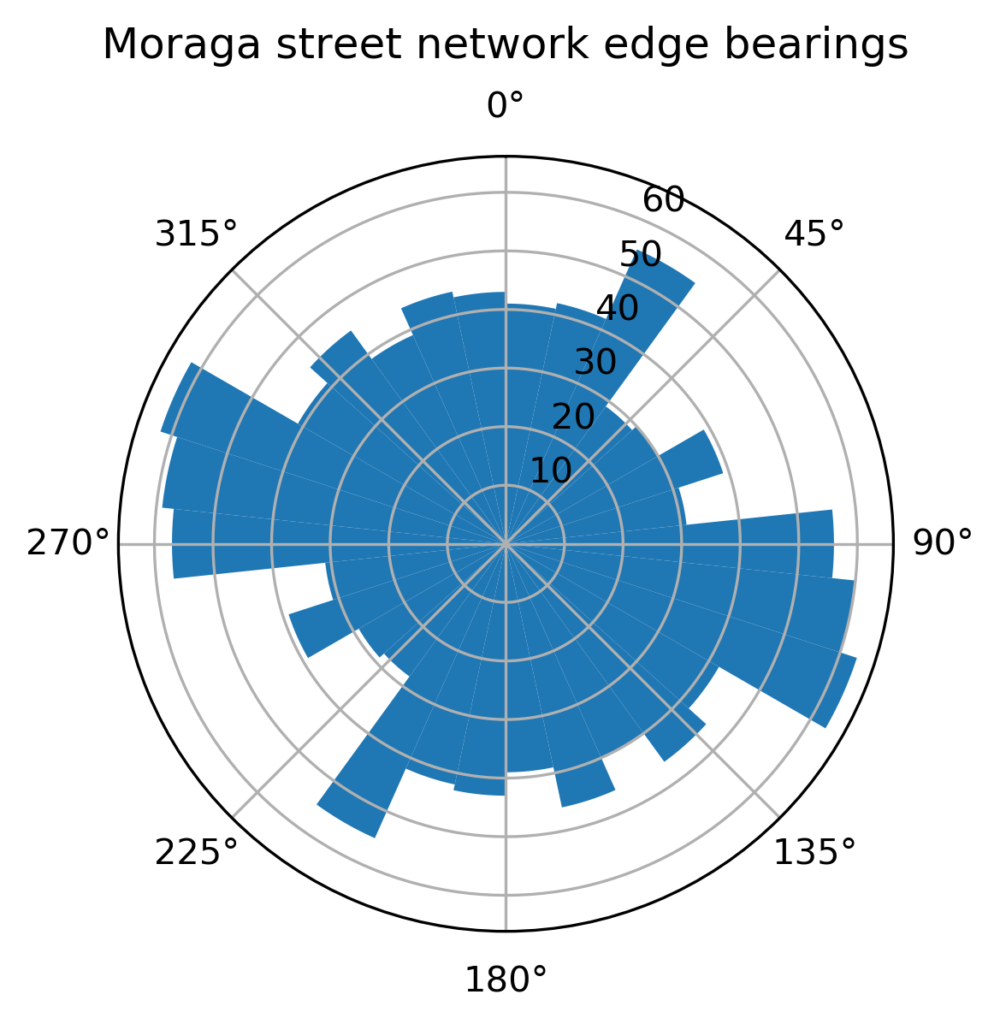
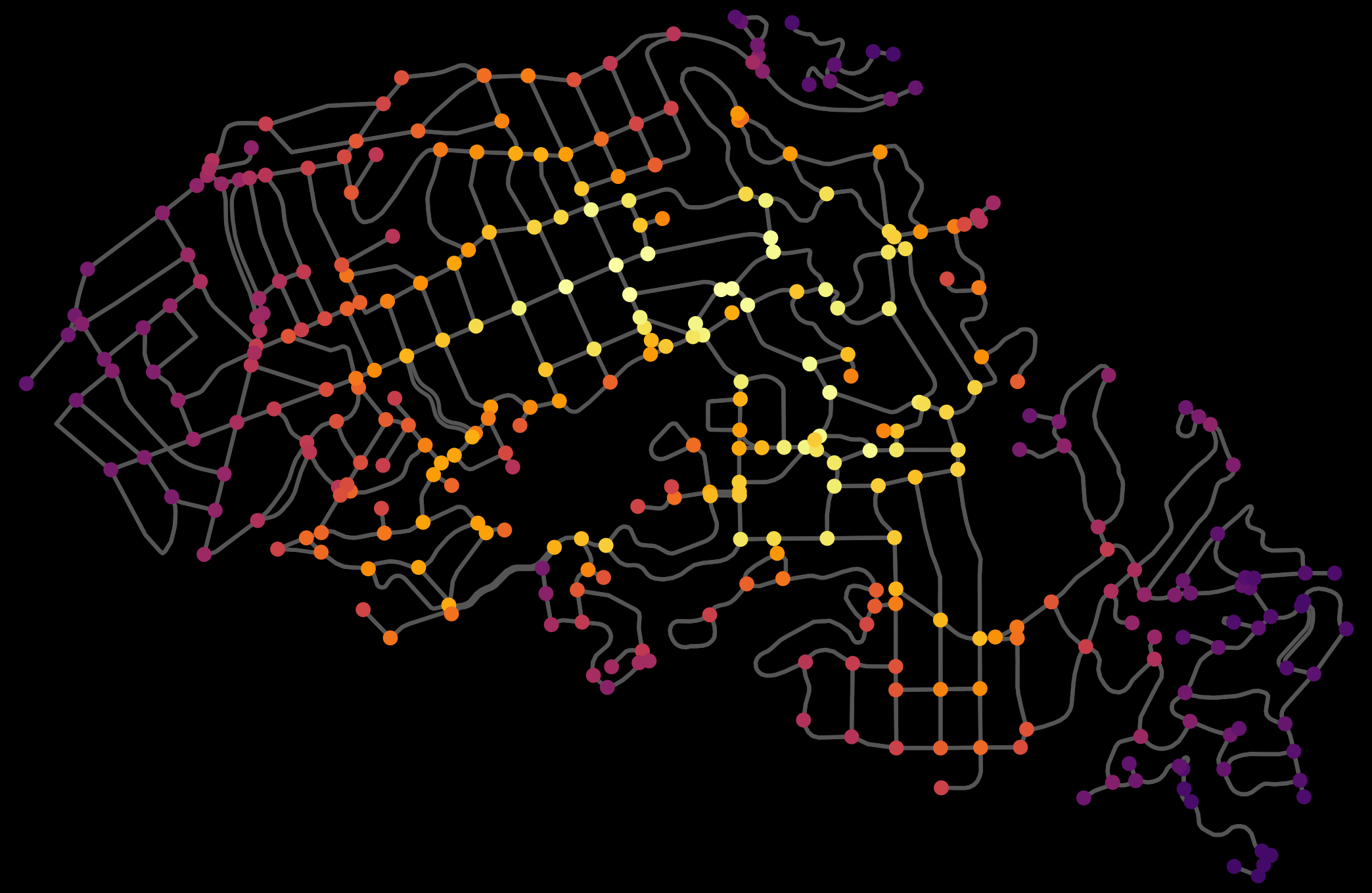
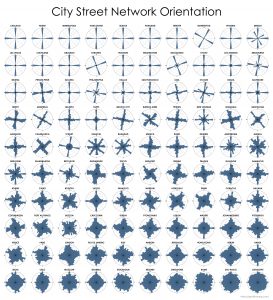 This post is adapted from this research paper that you can read/cite for more info. It analyzes and visualizes 100 cities around the world.
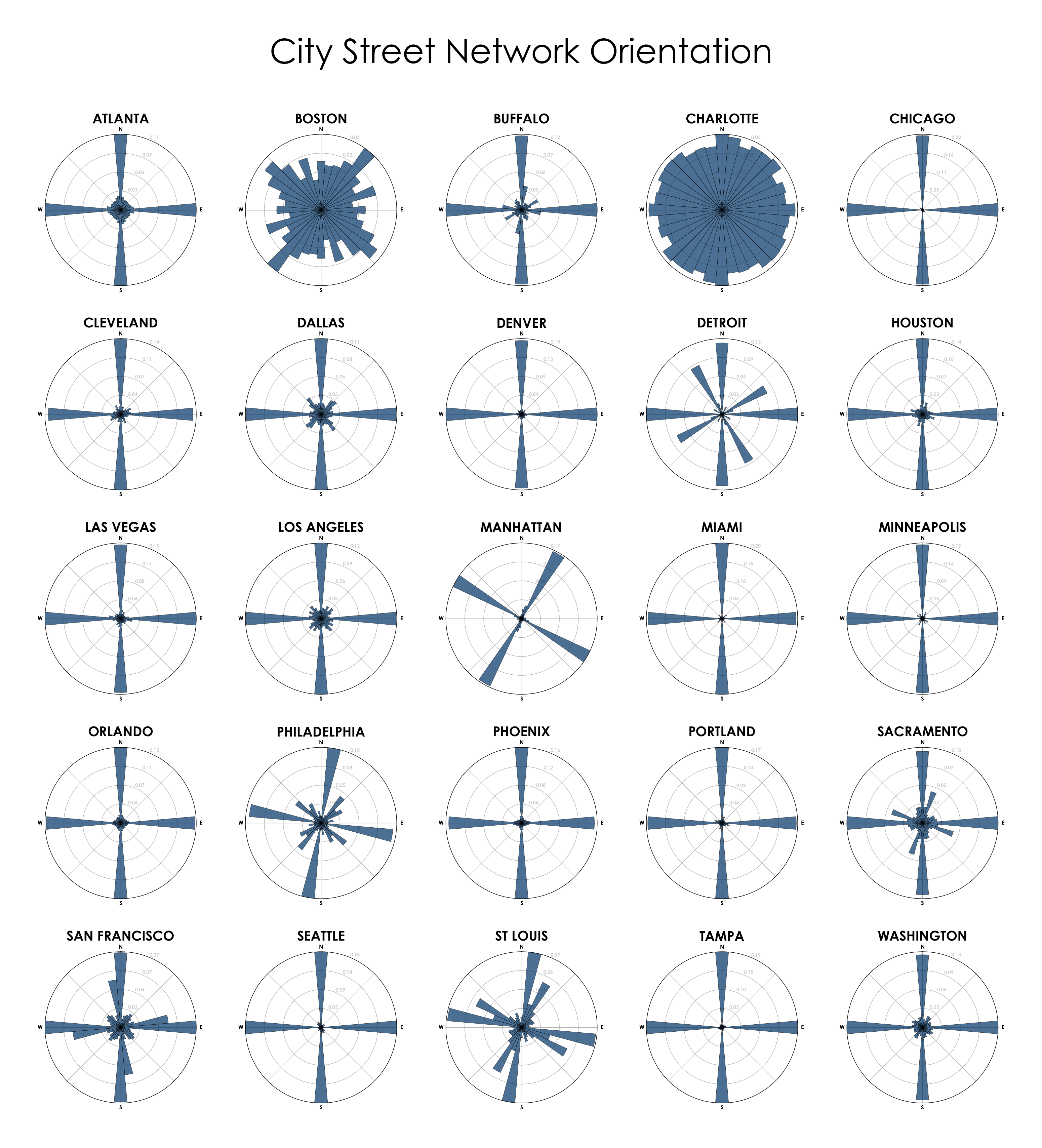
This post is adapted from this research paper that you can read/cite for more info. It analyzes and visualizes 100 cities around the world.