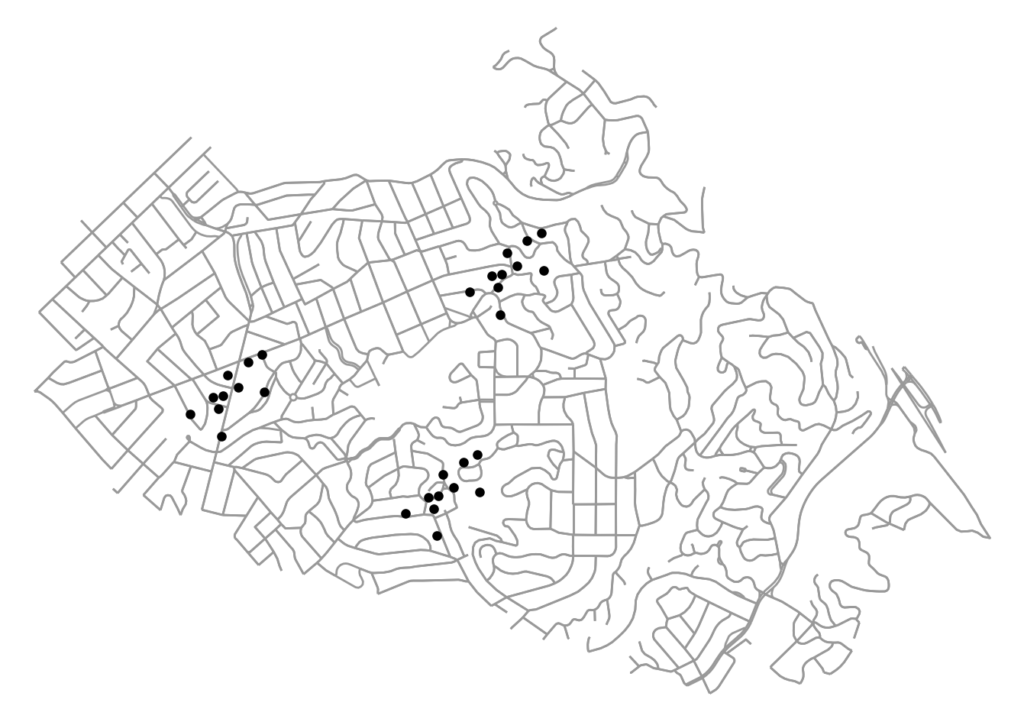
Jobs, establishments, and other amenities tend to agglomerate and cluster in cities. To identify these agglomerations and explore their causes and effects, we often use spatial clustering algorithms. However, urban space cannot simply be traversed as-the-crow-flies: human mobility is network-constrained. To properly model agglomeration along a city’s street network, we must use network-based spatial clustering.
The code for this example can be found in this GitHub repo. We use OSMnx to download and assemble the street network for a small city. We also have a dataframe of points representing the locations of (fake) restaurants in this city. Our restaurants cluster into distinct districts, as many establishments and industries tend to do: